Natural images captured by mobile devices often suffer from multiple types of degradation, such as noise, blur, and low light. Traditional image restoration methods require manual selection of specific tasks, algorithms, and execution sequences, which is time-consuming and may yield suboptimal results. All-in-one models, though capable of handling multiple tasks, typically support only a limited range and often produce overly smooth, low-fidelity outcomes due to their broad data distribution fitting.
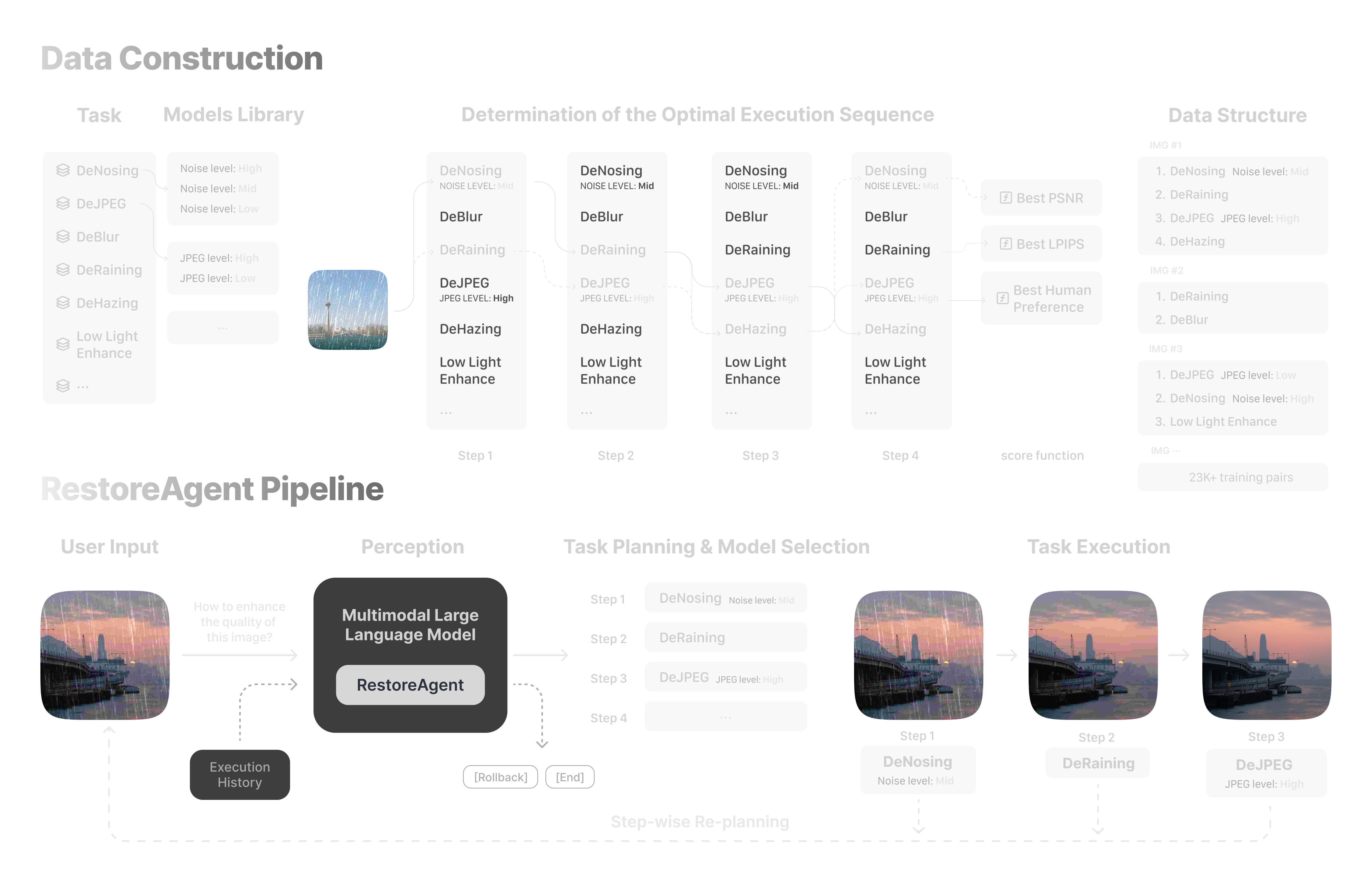
To address these challenges, we first define a new pipeline for restoring images with multiple degradations, and then introduce RestoreAgent, an intelligent image restoration system leveraging multimodal large language models. RestoreAgent autonomously assesses the type and extent of degradation in input images and performs restoration through
(1) determining the appropriate restoration tasks,
(2) optimizing the task sequence,
(3) selecting the most suitable models, and
(4) executing the restoration.
Experimental results demonstrate the superior performance of RestoreAgent in handling complex degradation, surpassing human experts. Furthermore, the system’s modular design facilitates the fast integration of new tasks and models, enhancing its flexibility and scalability for various applications.






Restore Agent
Autonomous Image Restoration Agent via Multimodal Large Language Models
1. Degradation Type Identification
RestoreAgent automatically identifies the types of degradation present in an input image and determines the corresponding restoration tasks required.
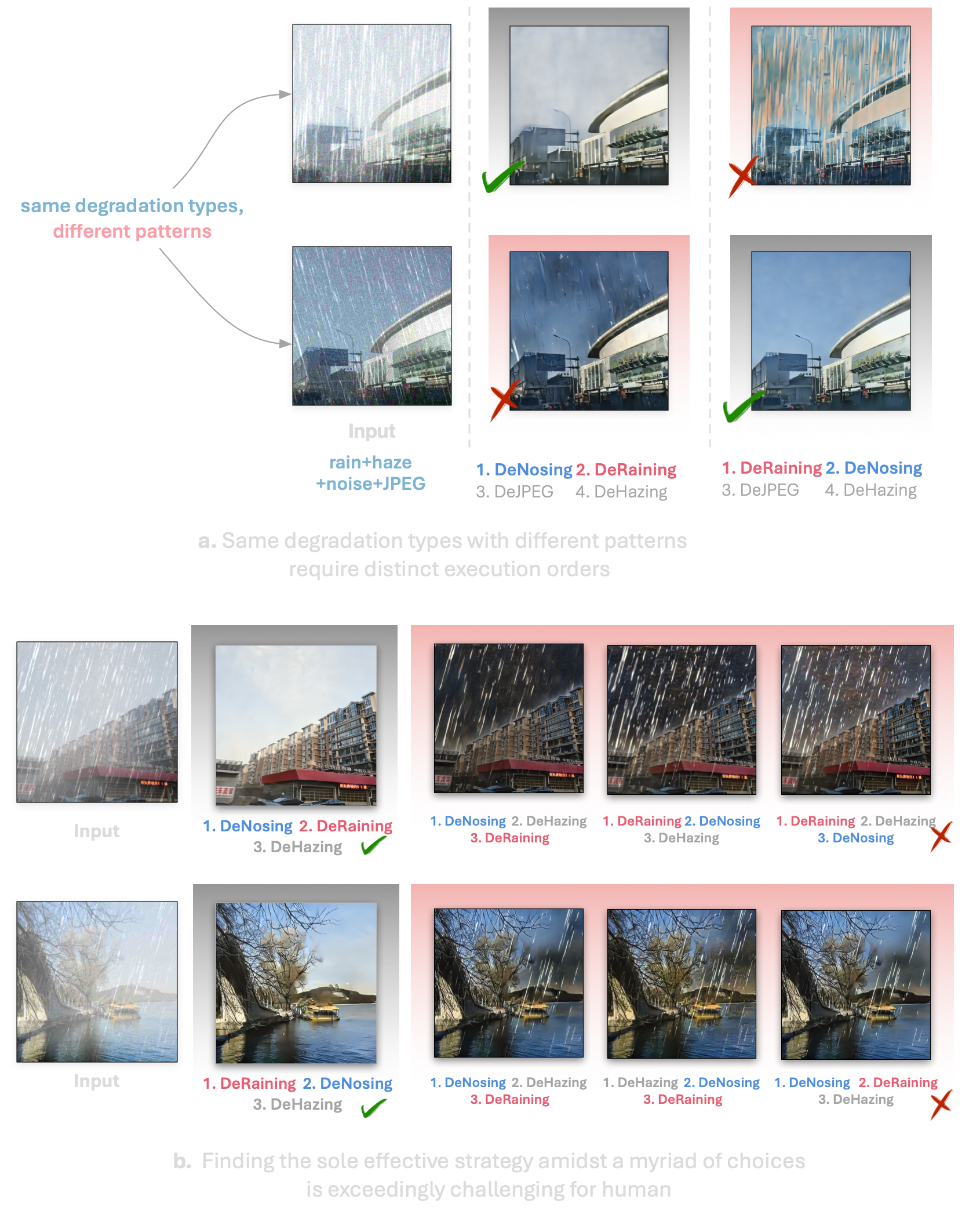
2. Adaptive Restoration Sequence
RestoreAgent surpasses the limitations of fixed, human-defined model execution sequences by adaptively assessing the unique characteristics of each input image to determine the optimal order for applying the restoration models, maximizing the effectiveness of the image restoration process.
3. Optimal Model Selection
Based on the specific degradation patterns in the input image, RestoreAgent dynamically selects the most appropriate model from the available pool for each restoration task, ensuring optimal performance.
4. Automated Execution
Once the restoration sequence and model selection are determined, RestoreAgent autonomously executes the entire restoration pipeline without the need for manual intervention.

| noise + JPEG | haze + noise | rain + haze + noise | rain + haze + noise + JPEG | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR ↑ | SSIM ↑ | LPIPS ↓ | DISTS ↓ | PSNR ↑ | SSIM ↑ | LPIPS ↓ | DISTS ↓ | PSNR ↑ | SSIM ↑ | LPIPS ↓ | DISTS ↓ | PSNR ↑ | SSIM ↑ | LPIPS ↓ | DISTS ↓ | |
| Real-ESRGAN | 23.43 | 0.7242 | 0.3022 | 0.2106 | - | - | - | - | - | - | - | - | - | - | - | - |
| StableSR | 17.61 | 0.4464 | 0.3705 | 0.2124 | - | - | - | - | - | - | - | - | - | - | - | - |
| AirNet | - | - | - | - | 17.56 | 0.5897 | 0.5569 | 0.2964 | 18.22 | 0.6767 | 0.4314 | 0.2336 | - | - | - | - |
| PromptIR | - | - | - | - | 16.13 | 0.5428 | 0.6696 | 0.3544 | 17.81 | 0.7099 | 0.4506 | 0.2317 | - | - | - | - |
| MiOIR | 23.98 | 0.6961 | 0.3266 | 0.2325 | 15.79 | 0.4790 | 0.7118 | 0.3628 | 16.22 | 0.6388 | 0.4719 | 0.2771 | 13.80 | 0.6410 | 0.4875 | 0.2939 |
| InstructIR | - | - | - | - | 17.36 | 0.4288 | 0.7696 | 0.3646 | 19.45 | 0.6897 | 0.3994 | 0.2170 | - | - | - | - |
| DA-CLIP | 22.47 | 0.6128 | 0.3525 | 0.2287 | 16.98 | 0.7061 | 0.3901 | 0.2737 | 15.44 | 0.6011 | 0.4597 | 0.2754 | 15.30 | 0.6863 | 0.3871 | 0.2627 |
| AutoDIR | - | - | - | - | 17.51 | 0.6942 | 0.4248 | 0.2444 | 19.22 | 0.7705 | 0.3043 | 0.1802 | - | - | - | - |
| RestoreAgent | 25.32 | 0.7806 | 0.2308 | 0.1958 | 20.47 | 0.8053 | 0.2193 | 0.1758 | 19.53 | 0.8237 | 0.2166 | 0.1638 | 19.72 | 0.7816 | 0.2741 | 0.1903 |

| PSNR ↑ | SSIM ↑ | LPIPS ↓ | DISTS ↓ | balanced ↑ | ranking ↓(%) | |
|---|---|---|---|---|---|---|
| Random Order & Model | 21.31 | 0.7139 | 0.3246 | 0.2241 | 1.92 | 34.7 |
| Random Order + Predict Model | 21.74 | 0.7385 | 0.2848 | 0.2045 | 2.89 | 26.1 |
| Random Model + Predict Order | 22.42 | 0.7574 | 0.2750 | 0.2027 | 3.44 | 22.7 |
| Pre-defined Order and Model | 22.38 | 0.7639 | 0.2644 | 0.1986 | 3.48 | 22.1 |
| Human Expert | 22.51 | 0.7634 | 0.2670 | 0.2014 | 3.73 | 19.5 |
| RestoreAgent | 22.61 | 0.7700 | 0.2513 | 0.1890 | 4.38 | 12.9 |
BibTeX
@misc{chen2024restoreagent,
title={RestoreAgent: Autonomous Image Restoration Agent via Multimodal Large Language Models},
author={Haoyu Chen and Wenbo Li and Jinjin Gu and Jingjing Ren and Sixiang Chen and Tian Ye and Renjing Pei and Kaiwen Zhou and Fenglong Song and Lei Zhu},
year={2024},
eprint={2407.18035},
archivePrefix={arXiv},
primaryClass={cs.CV}
}